So, I want to talk about safety and autonomy. I am not an expert on this topic (though I do have a background in robotics), but some larger considerations are being missed in the current debate. People go back and forth on how long it will be until Level-4 self driving “arrives”. But nobody ever steps back to the meta-level to consider if this was the right problem in the first place.
Real-world deployment of learning based systems in non safety-critical environments should be leveraged to accelerate their rollout in safety critical applications. The current approach - starting by solving problems that simultaneously stretch current algorithms’ capabilities and need approaching 0% failure rates was almost guaranteed to be a huge challenge.
Self-driving is an instructive lens through which we can view the challenges of the rollout of autonomy. Billions have been poured into autonomous vehicle companies. However, we have yet to see the scaled deployment of this technology. What went wrong?
You should watch this excellent talk from Richard Murray, which gives a detailed sense of what it will take to ensure safety in autonomous systems.
In the US 1, there are
- 7 deaths per billion miles of driving
- 0.1-0.4 deaths per billion miles on public transport
- 0.07 deaths per billion miles of flying
The first death from a prototype self-driving system was extremely widely publicised at the time, and continues to be discussed two years after. If the rollout accelerates, not every death will be publicised to this extent. At 1 fatality per billion miles (an order of magnitude better than humans), you would get at one death per day in California. Even if every single one is not national news, this would make for like quite a few law-suits indeed; is probably not sustainable.
Since autonomous vehicles must be perceived to be superior to human drivers, we can take this 1 fatality / billion miles figure as a high upper bound on acceptable safety rates.
Vision systems are unacceptably flaky when deployed on current level-2 systems. Errors are both far too common and unpredictable - more progress is needed on robustness in this area.
On the planning side, analysis of progress on the learning side paints a bleak picture. Heuristic + algorithm based approaches do not generalise very well; Reinforcement Learning methods currently have very poor sample efficiency. Neither has safety guarantees attached.
It is clear that more progress is needed on both the algorithms and data collection fronts for both perception and planning.
Scaling capability safely
There are two crucial questions to be asked when deploying an autonomous system - robustness and capability.
The capability question has largely been answered by massively scaling neural networks. Current methods may not be able to do everything, but it seems likely that with sufficient data, they will eventually be able to amply generalise.
Robustness remains a challenge because:
- To produce highly capable and robust learning-based systems, you have to have trained them on a dense and representative distribution to ensure they have fully explored the state / action space.
- To have systems that are safe, you need to first validate them on a representative sample (or else prove formally that they are safe - good luck doing that with a deep net!). One estimate puts this figure potentially as high as tens of billions of miles.
The raw capability of the learning algorithms has outstripped what can be verified, leading to a safety deficit in these cutting edge systems:
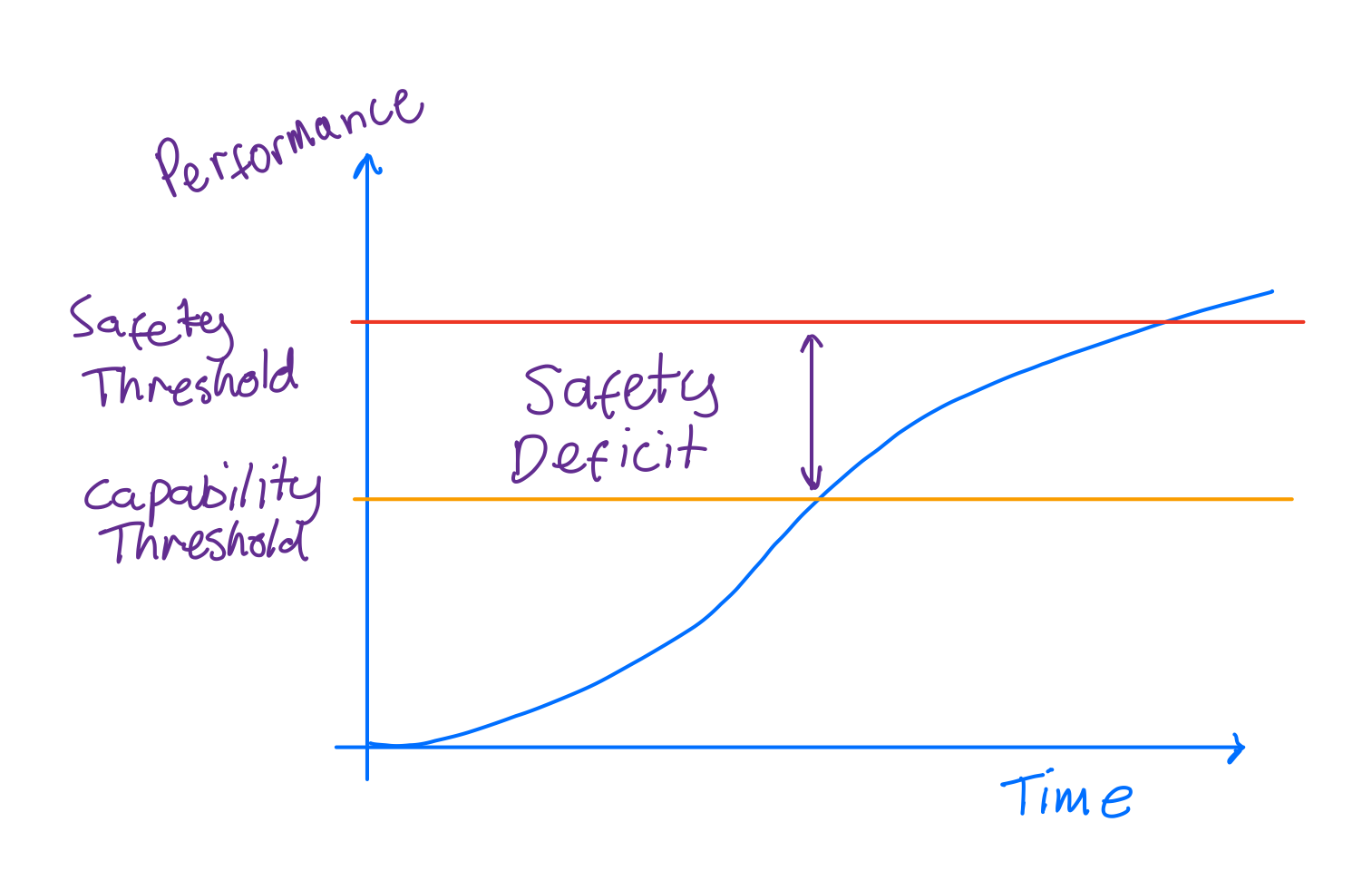
This is borne out if you look at the recent history of self-driving. Machine Learning combined with exponentially increasing compute enabled rapid improvement of the capability of these systems, but they have not yet achieved the robustness required to climb the tricky part of the sigmoid curve of performance.
The safety deficit results in a classic chicken and egg problem: you can’t gather enough data to train your models and ensure the system is robust, but to gather this data you need many systems in production.
Taking a broader view we can approximately plot the safety and data requirements for different systems:
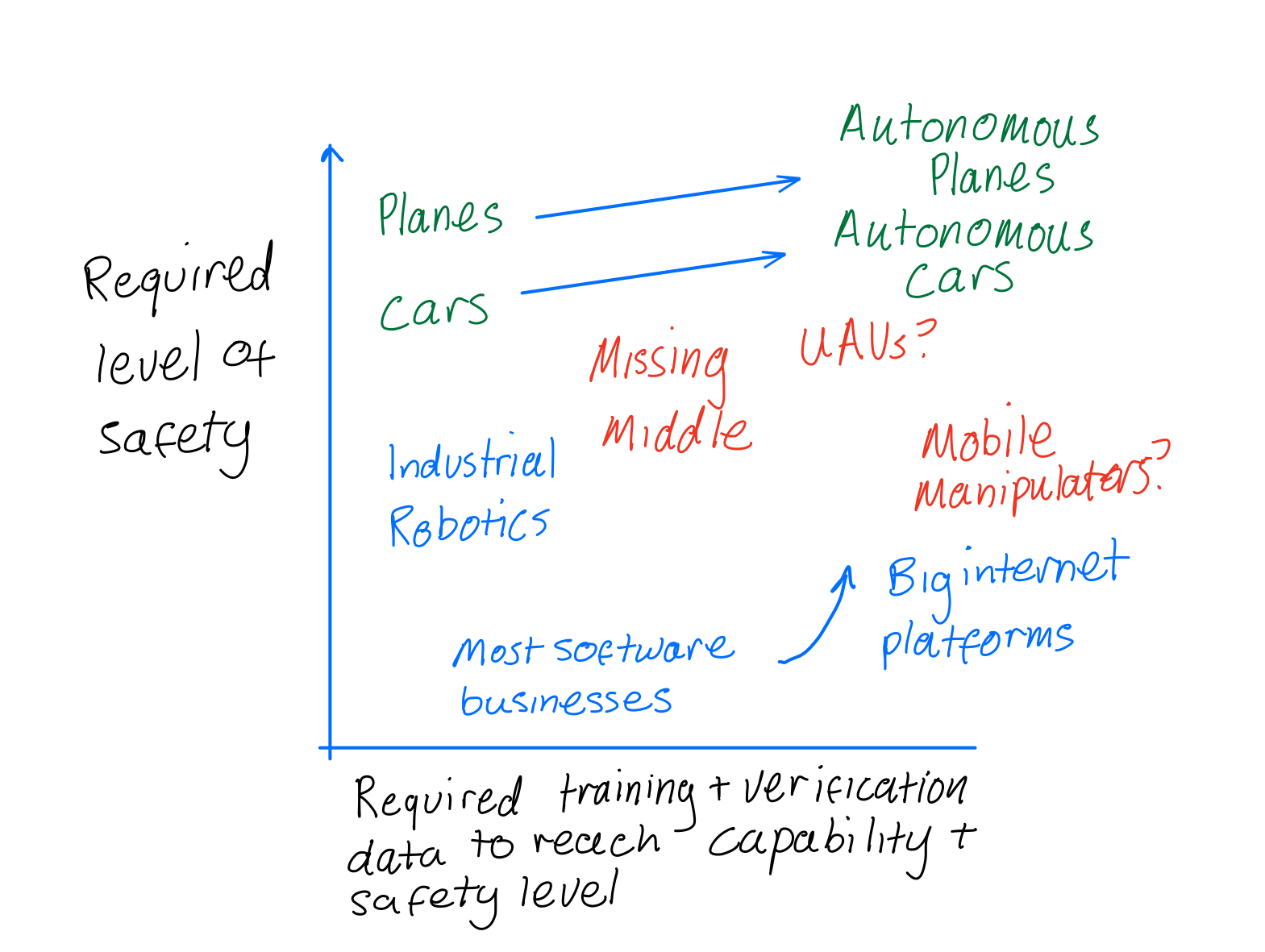 Safety levels required of various systems vs amount of empirical data that must be gathered to attain required capability level and verify this safety. The missing middle (red) indicates the application areas the Robotics community should try and achieve more wide scale deployment of.
Safety levels required of various systems vs amount of empirical data that must be gathered to attain required capability level and verify this safety. The missing middle (red) indicates the application areas the Robotics community should try and achieve more wide scale deployment of.
What becomes apparent is how current successes lie close to one of the axes on either training + verification data requirements or safety requirements.
Autonomous cars push the boundaries on both axes: they both must have failure rates comparable to existing transportation systems due to their safety critical nature, and they require the most cutting edge algorithms ever built.
In this model, it becomes apparent why self-driving was the wrong problem to choose. The extremely high safety requirements mean that large deployment in the hands of real users has been impossible. The result has been sub-scale deployments funded up-front and slow progress.
We should seek application areas for learning algorithms in the/missing middle, shown in red in the chart above. These application areas push the boundaries on the performance of current-generation learning algorithms, but which allow for safe exploration of their action space.
Such agents can continually improve from the data collected while being safe doing so. In this model, capability is the bottleneck:
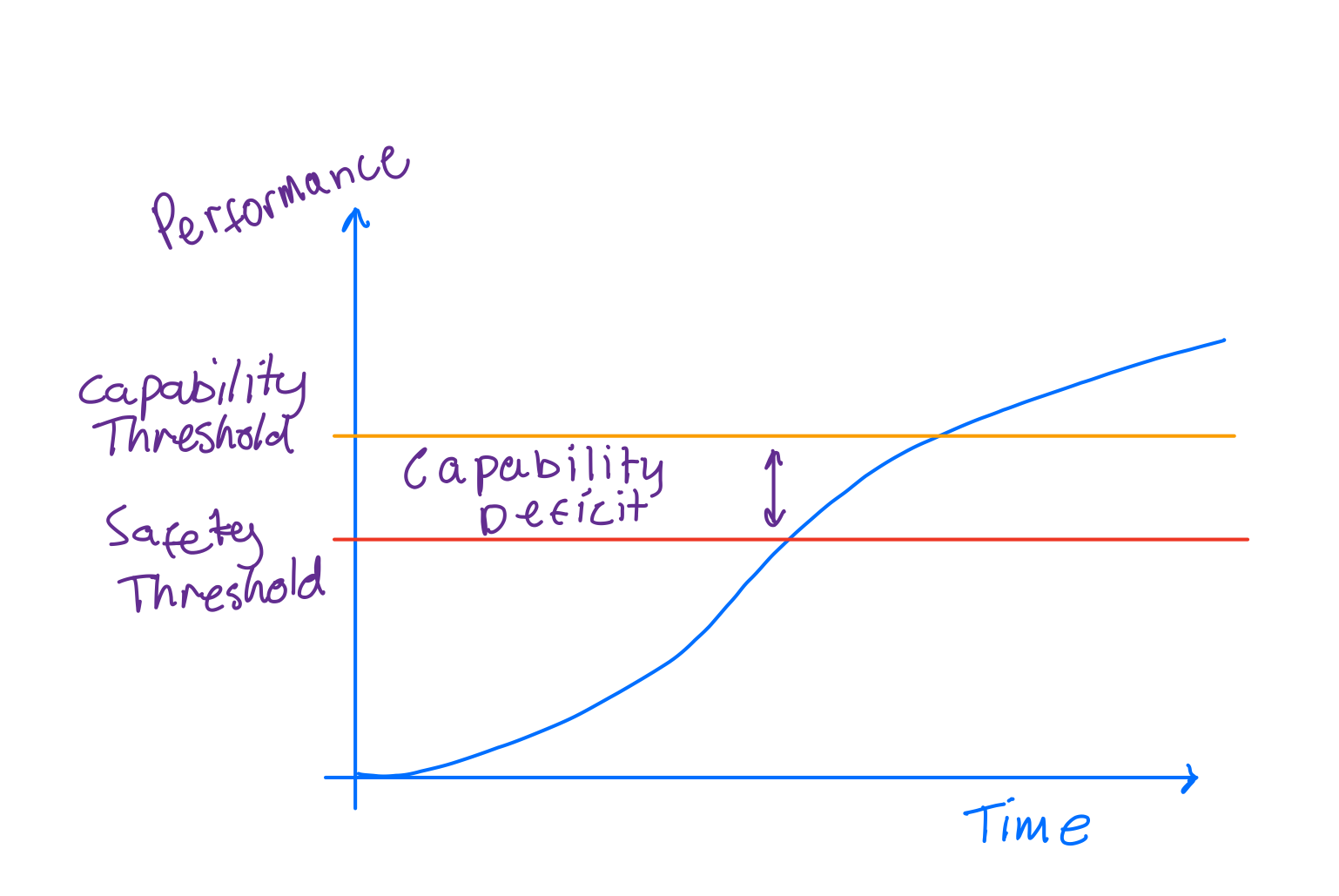
When you take this approach, by the time you get systems that are marginal on capability, they will also satisfy the safety requirements of the problem at hand. Once this threshold is met, you can start pushing the technology into application ares.
This will lead to a positive feedback loop. More deployment will lead to more data leading will lead to better systems and hence more deployment. The classic technology climbing of the sigmoid curve will be the result.
It makes sense to target application areas with a) lower safety verification requirements, and b) that can be trained with less data (either due to the nature of the problem, or through training in simulation).
The canonical example of this from the past is industrial robots. You can bound the design domain, and nobody is going to die because of a wrong controller input (in many cases you can remove human interaction from the equation entirely). Autonomous mining trucks are a more recent example of a truly autonomous system operating in an unstructured environment.
Robots pushing into domestic spaces are a promising opportunity. If mobile manipulators can be made to work they could reduce labour requirements in many sectors. As does low-speed transportation (for example in pedestrian spaces). In both of these cases, the operational domain is such that small errors do not lead to large safety risk.
Making the economics work in these scenarios is a vital piece of the puzzle. Drone delivery systems are in instructive failure in this space: the technology is relatively safe and the algorithms mature. Yet deployment outside of very specific settings has been impossible - drone delivery simply cannot compete on price with a fleet of vans.
Does this mean that the self-driving project is doomed? No. There are multiple companies chipping away at the issue. The most sensible approaches are by Waymo with huge scale simulation, and Tesla using data to bootstrap a level-4 autonomous system from a level-2 one.
These may or may not be successful. For practitioners looking for a faster route to the frontier, I think that there are smarter routes towards improvement of robotic systems operating in unstructured environments.
Thanks to Ben Agro and Shrey Jain for reading drafts of this.
-
Hence the imperial units. ↩︎